Data lineage
When working with large amounts of data, extraction, transforms and loads procedures can hide the source of the original data and make inquiries on "where did this data come from and what happened to it?" difficult to answer.
A data lineage is "the process of understanding, recording, and visualizing data as it flows from data sources to consumption1" and tries to answer that question.
Using dataflow and ETL orchestration tools such as Airflow, Prefect, NiFi, we move and transform data, but also lose the reference as to how the data was transformed.
In this document, we will approach one open source tool OpenLineage and one "hand built" approach to capturing and storing data lineage information.
OpenLineage and Marquez - Open source tools
OpenLineage is an open source project and framework for data lineage collection and analysis that helps collect lineage metadata from the data processing applications. At its core, OpenLineage exposes a standard API for metadata collection - a single API call: postRunEvent.
To simplify its implementation with AirFlow, Open Lineage has an airflow connection module already available.
On the back-end, the storage of run meta-data has a reference implementation named Marquez. The data model is illustrated here.
But it is also possible to implement one's own storage for metadata in case there is a need or added value, but adopting the open source solution will be an advantage for integration later.
Locally grown alternatives
Data correlation and lineage information can be generated via the emission of events while processing input data. Additionally, input data can be fingerprinted via a fast hash function to check for duplicate imports, so as to enable idempotent processing.
Input dataset fingerprinting via non-cryptographic hash function
We can use a fast non-cryptographic hash function such as umash to generate a hash of the input data or xxhash sudo apt-get install xxhash. xxhash is capable of taking streaming STDIN data from compressed files to generate a fast hash.
time gunzip -c /mnt/d/smart_meter_data/ckw_opendata_smartmeter_dataset_a_202101.csv.gz | /usr/bin/xxhsum
Correlation IDs with UUIDs
Generating uuid for correlations identifiers along rfc4122 gives us multiple variant generation algorithms to give us sortable UUIDs which minimize collision possibilities even with a high UUID generation rate.
Hierarchical correlation IDs using closure tables
When inputs contain a dataset that is composed of multiple data points that identify unique sets in our final processed dataset, it becomes necessary to be able to trace their lineage back to the initial input. A recursive search through a table of entries to find the parent correlation identifier of a child time-series is quite inefficient.
To have fast search over deep hierarchies of correlations IDs in relational databases, we can turn to the concept of closure tables.
| Field | Type |
|---|---|
| ParentId | UUID |
| ChildId | UUID |
| Depth | integer |
This table structure allows to query in one query all parent or children of an identifier in one non-recursive sql query. This is done at the cost of having to insert the entire hierarchy of the correlationIDs upon insertion.
Here we are representing the two hierarchies
aaa > bbb > ccc
aaa > eee
| ParentId | ChildId | Depth |
|---|---|---|
| aaa | aaa | 0 |
| bbb | bbb | 0 |
| ccc | ccc | 0 |
| eee | eee | 0 |
| aaa | bbb | 1 |
| bbb | ccc | 1 |
| aaa | ccc | 2 |
| aaa | eee | 1 |
note: if desired the initial 0 depth nodes can be neglected from the insertion process without losing functionality, but can be useful in certain modeling processes (eg. rights, groups)
If we need to find all children of aaa, we can do a
SELECT ChildId, Depth FROM Closure_Table WHERE ParentId = "aaa" ORDER BY Depth;
which returns the following
| ChildId | Depth |
|---|---|
| aaa | 0 |
| bbb | 1 |
| eee | 1 |
| ccc | 2 |
If we need to find all parents of eee, we can do a
SELECT ParentId, Depth FROM Closure_Table WHERE ChildId = "eee" ORDER BY Depth DESC;
which returns the following
| ParentId | Depth |
|---|---|
| aaa | 1 |
| eee | 0 |
Table structure for a Correlated, fingerprinted hierarchical data lineage
With correlatedEvent and CorrelatedLineage tables, it becomes possible in a single request to generate a lineage graph for parents or descendants of correlated dataset.
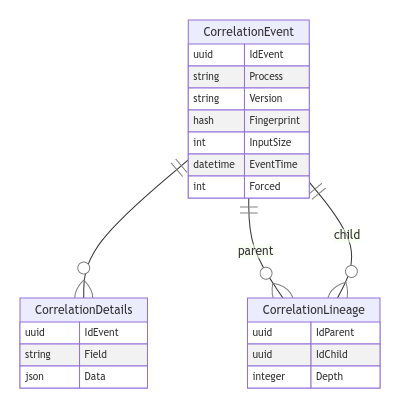
erDiagram
CorrelationEvent {
uuid IdEvent
string Process
string Version
hash Fingerprint
int InputSize
datetime EventTime
int Forced
}
CorrelationDetails {
uuid IdEvent
string Field
json Data
}
CorrelationLineage {
uuid IdParent
uuid IdChild
integer Depth
}
CorrelationEvent ||--o{ CorrelationDetails : ""
CorrelationEvent ||--o{ CorrelationLineage : "parent"
CorrelationEvent ||--o{ CorrelationLineage : "child"
It would even be possible to generate the diagrams using mermaid automatically to trace the flows through the system2.
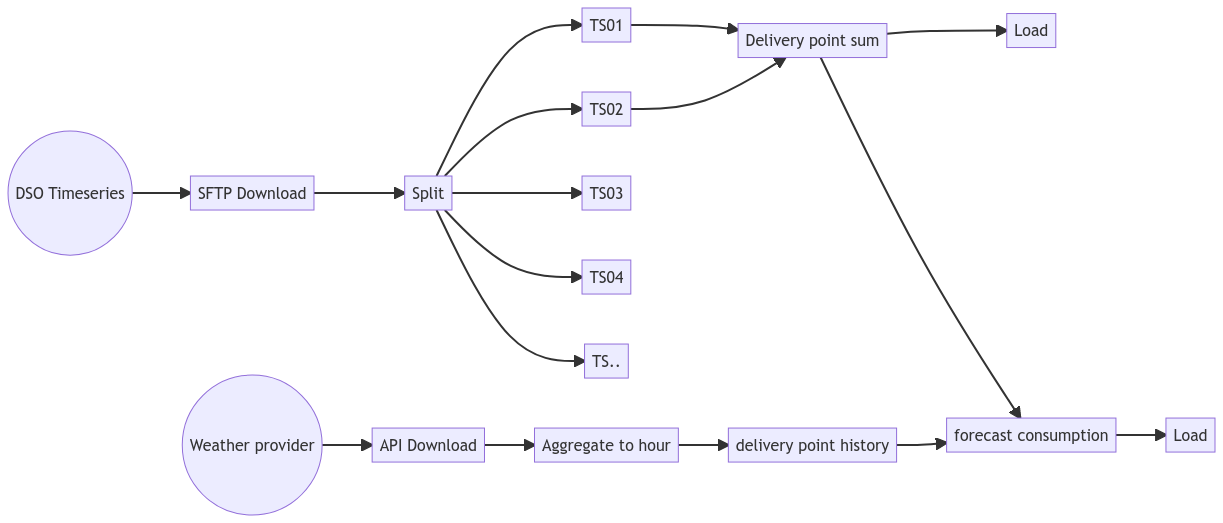
flowchart LR
id1(("DSO Timeseries")) --> id2[SFTP Download] --> id3[Split]
id3 --> TS01
id3 --> TS02
id3 --> TS03
id3 --> TS04
id3 --> TS..
TS01 --> id4[Delivery point sum]
TS02 --> id4
id4 --> id5[Load]
met((Weather provider)) --> met2[API Download] --> met3["Aggregate to hour"] --> met4["delivery point history"]
met4 --> for1[forecast consumption]
id4 --> for1 --> for2[Load]
Solution design
A rabbitMQ message queue to receive correlation events emitted by the tasks, with several consumer tasks receiving and committing to the database is a preferred approach over an HTTP 1.1 connection due the the scaling efficiency of AMQP over pure HTTP3.

flowchart LR
a[Airflow] ---> b[AirFlowTask] --> c[[RabbitMQ Queue Events]] --> d[EventReceiver] -- success --> g[(Postgresql)] --> Monitoring
d -- failed --> e[[RabbitMQ Queue Deadletter]] --> f[DLQ processing and Reconciliation] --> g
A particular focus on the monitoring of the solution is necessary to truly have an operational system. The RabbitMQ should be a redundant, instrumented and reported to Graphana, with a queue length monitoring in place. The EventReceivers should employ a dead letter queue in case message are rejected by the database. These rejected messages could also also be a uuid collision - which can be treated by the daily reconciliation process and DeadLetter queue processing.
A high availability Postgresql is recommended, either as a local instance or as a cloud hosted service - which would facilitate operations.
The issue of Data retention should be discussed with Business. If we do not keep a time-series history in the time-series datastore, then the event correlation become actually an event sourcing pattern, enabling to re-create the history of how the time-series was updated.
Conclusion
Irrespective of the method chosen to capture and store the messages, the systems chosen must provide a high availability solution for data lineage - but must be sure to not block ingestion if the data lineage system is unresponsive. As long as the message queue is persistent and accessible, it can always be caught up later.
The main task is emitting the events with meaningful data and unique correlation IDs. A focus on the semantics of the events while developing the workflow / dataflows is primordial. A callable event library provides the best developer experience to maximize standardization of code
The design of idempotent imports into the system is important, it allows to replay events non-destructively and provides operational resilience.
-
https://github.com/dotnet/interactive/blob/main/samples/notebooks/polyglot/github%20repo%20milestone%20report.ipynb - See the PieWithMermaid C# task for a visualisation of such an interaction.↩
-
This should be re-evaluated when HTTP/3 oneshot becomes available in the servers and languages used. The expected performance improvement are such that at that time HTTP/3 QUIC might outrace any other streaming solution. https://blog.cloudflare.com/http3-the-past-present-and-future/↩